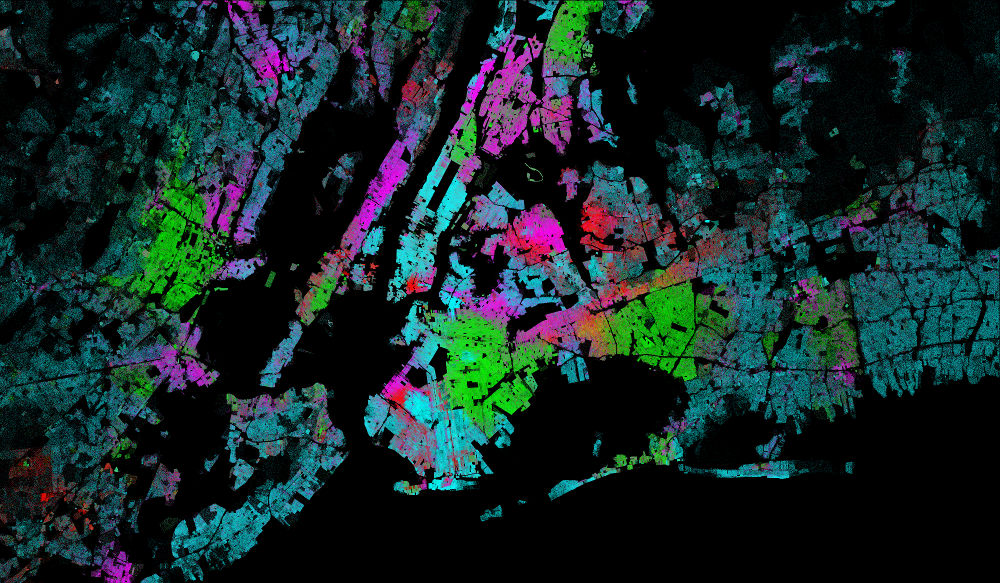
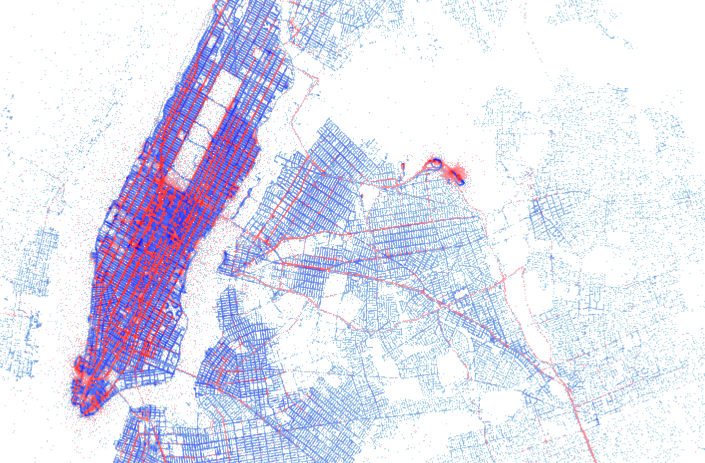
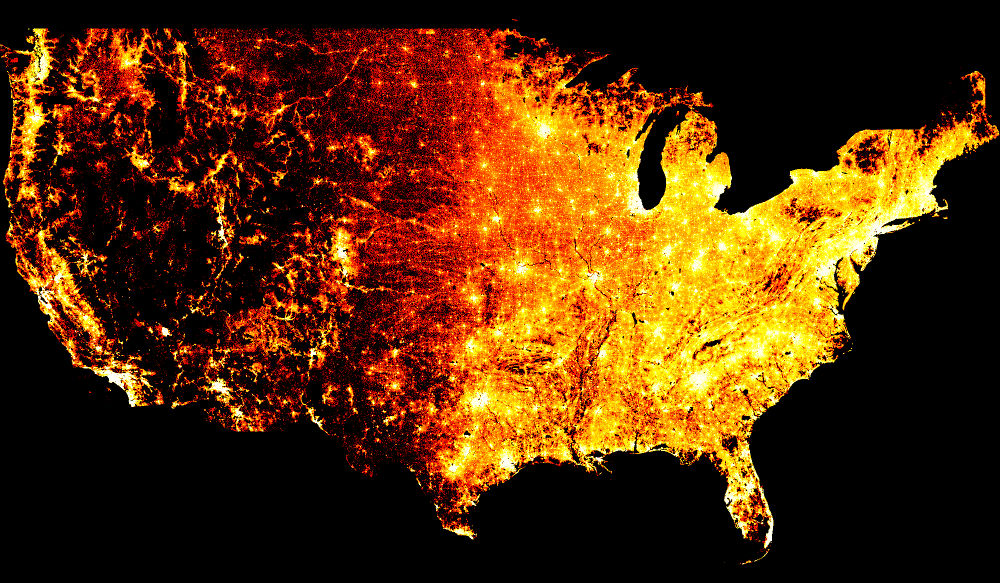
datashader is a library that provides a flexible pipeline for doing bin-based rendering of large datasets. datashader is independent of Bokeh, but is designed to work well with it, providing raw images that Bokeh can then annotate, format, and display interactively.
Features:
- Provides automatic, nearly parameter-free visualization of datasets
- Allows extensive customization of each step in the data-processing pipeline
- Supports automatic downsampling and re-rendering with Bokeh and the Jupyter notebook
- Works well with dask and numba to handle very large datasets in and out of core (with examples using billions of datapoints)
The new features are described at https://github.com/bokeh/datashader/releases, including legends, hover support, colormaps, backgrounds, compositing, point sizing/shapes, line plotting, and new examples of Census data, time series data, and trajectories. And it’s now even faster.
Datashader can be installed using:
conda install datashader
and extensive examples are available as Jupyter notebooks at:
https://anaconda.org/jbednar/notebooks
Jim