I am working on a multi-class classification app in bokeh server (version 2.0.2), which can have 30-40 classes in a typical use scenario. At present, the updating of graphics is responsive and quick.
However, the initial session startup can take approx. 2-3 seconds for the server side work to generate models and plots. A lot of the graphics are common among the plots and can be carried out in an iterator over the number of classes.
Conceptually, it is straightforward to leverage the multi-core CPU and multiprocessing capabilities (either through python’s multiprocessing or pathos’ multiprocess) to lessen the startup time.
I am running into similar problems as cited in this stackoverflow topic related to multiprocessing as it pertains to bokeh. The failure mode depends on whether using core python multiprocessing (e.g. often fails due to pickling limitations of lambda functions used in bokeh) or pathos’ multiprocess, but both methods are unsuccessful.
Are there any success cases in distributing bokeh server-side computations to take advantage of multi-core CPU? My use case/problem is different than that in the cited stackoverflow topic, in that I am narrowly focused on startup time of sessions.
An example of the error when trying to concurrently generate multiple figures via multiprocessing pools follows.
@p-himik, Thanks for the perspective. I’ve moved on to other approaches to lessen startup time. As you’ve alluded to in your response, I am constrained in how I can distribute the work given the bokeh objects (figures, glyphs, etc). I’ve tried farming out the work to CPU cores at various levels of the layout process and using the multiprocessing, pathos-multiprocess, and ray packages each unsuccessfully in different ways because of how bokeh objects are organized.
To your question(s), the startup time is certainly governed by the models in this case and not the data that underlies them. Specifically, it is because I have many plots (30-50) and I am layering a few areas and boundaries that serve as a reference on acceptable performance in my application.
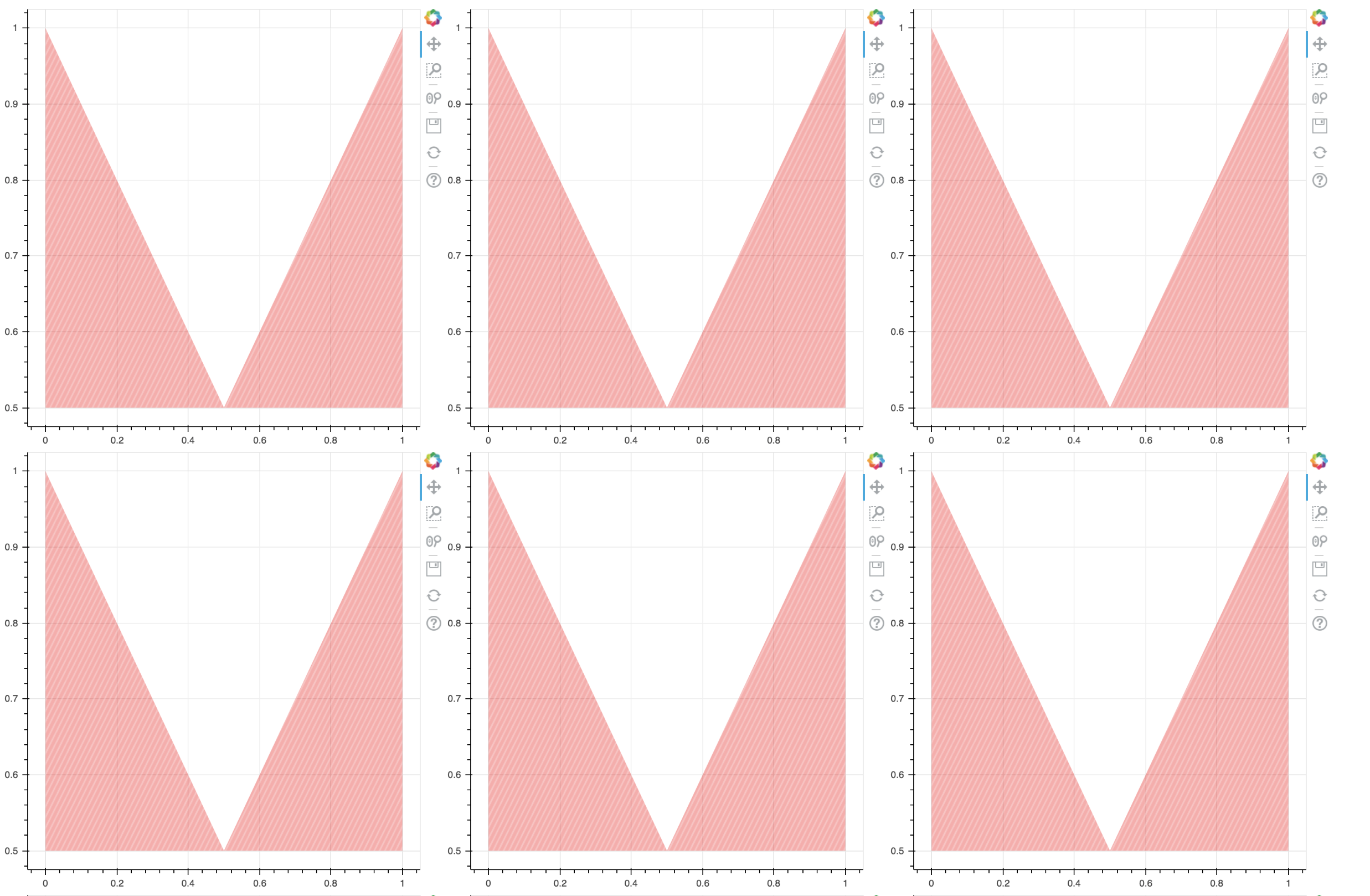
For one of the performance metrics, the main layout looks something like the following, i.e. two VAreas with hatching, and a “V” shaped boundary curve. I only need a few points in my data sources to define these shapes. There is some additional axis formatting, annotations, and such going on but the rendering of these plots before I add the actual engineering data for a given problem is the focus of my optimization.
Thanks again for always providing informative insight regardless of the question/topic.
Just to add some different comments: Bokeh models are not pickle-able. This is for several reasons, but chiefly it is is due to the fact that a single Bokeh model is not considered serializable on its own. Bokeh models are owned by a singe document, and may refer to other models. The smallest “unit” of serialization is a Bokeh Document which will have a transitive closure of all models “reachable” from the root.
So, TLDR if you want to distribute work, that’s fine. But you can’t use Bokeh models themselves to communicate between processes. More concretely, you could have one process compute a CDS .data dict and send that data to another, to be added to a new CDS in the receiving process. But you can’t send an actual CDS model itself.