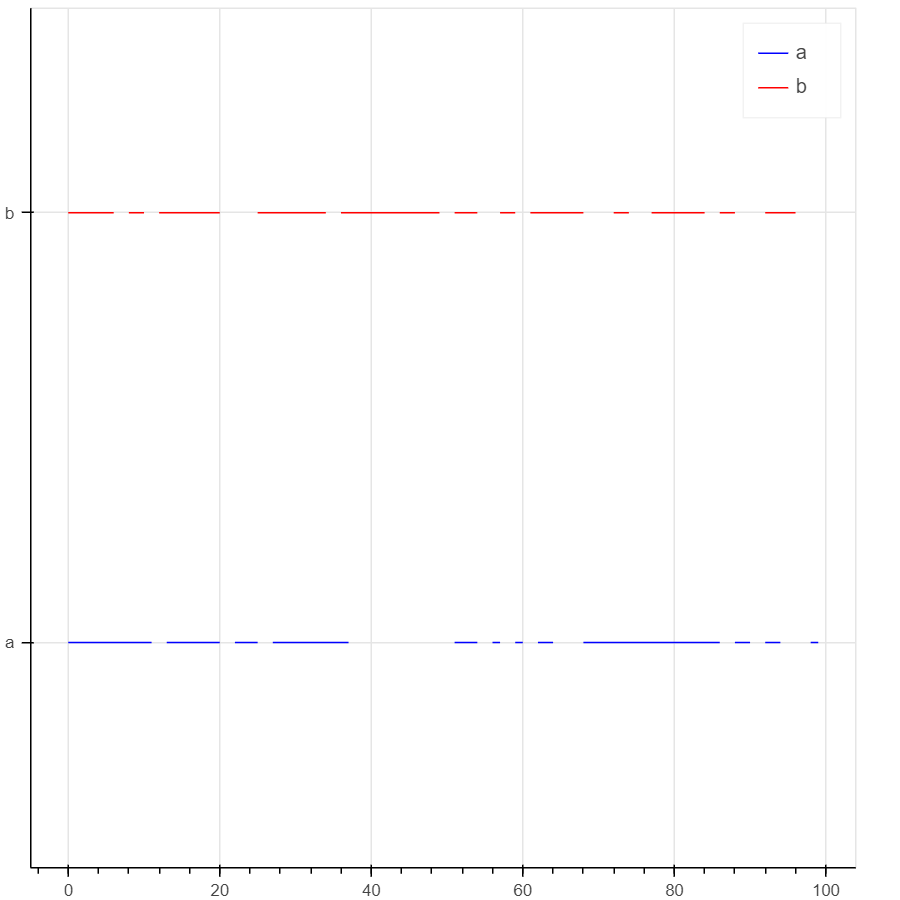
My Goal:
Create a plot with a dictionary’s keys on the y axis, and it’s values (which are lists specifying a range of numbers) that appear as either a series of discrete or continuous glyphs on the x-axis - the measures should be vertically separated by some distance (like you’d see in an hbar). The twist: The ranges are not continuous.
My Problem:
Suppose I have a dictionary:
data = {'a': [0, 1, 2, 3, nan, nan, 6, ..... 99999, 10000],
'b': [0, 1, nan, 3, nan, 5, 6, ..... 99999, nan]}
I added nan values into each list to ensure that value was the same length (10000 in this example), because this is a required property for the ColumnDataSource.
I thought I might need to specify the names of the keys and values of data for glyph rendering and axis specification:
taxa = list(data.keys())
values = list(data.values())
source = ColumnDataSource(data=data)
p = figure(y_range=taxa, height=250, x_range=(x_min, x_max), title="Coverage by Taxa",
toolbar_location=None, sizing_mode="stretch_width")
Then, I tried a few different methods of glyph rendering:
p.circle(x='values', y=jitter('taxa', width=0.6, range=p.y_range), source=source, alpha=0.3)
p.hbar_stack(values, y='taxa', height=0.9, color=GnBu3, source=source)
p.line(x='values', y='taxa', source=source, line_width=2)
It may very well be that I am just using one of the above incorrectly, but in examples I’ve found I’ve never seen these non-continuous ranges plotted before via Bokeh.
In every case, I’m not getting anything plotted, and I’m getting the error:
ERROR:bokeh.core.validation.check:E-1001 (BAD_COLUMN_NAME): Glyph refers to nonexistent column name.
The figure is getting created though - looks something like this:
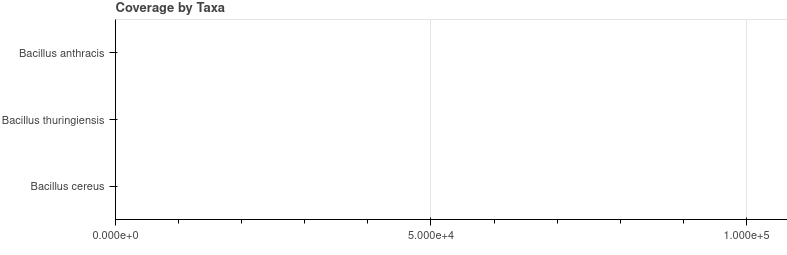
In my debugger, I looked inside of source and discovered that the column names do correspond to the keys of the dictionary (what I need for the y-range). But I have no idea about the numerical values - could it be the data attribute?
I want the final graph to look something like this:
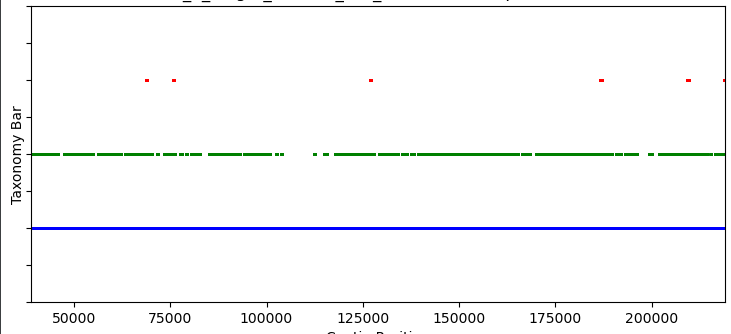
Which glyph renderer should I use for this? And what can I specify for ‘x’, exactly?
Thanks.