Simply I want to create a pivot table in a standalone file, no servers or outside help. Of course the values of the pivot table will be taken from the selected CDS.
How can I get around this? Extending Bokeh is extremely overwhelming for me to understand at this point. Baby steps would be appreciated.
A pivot table can mean a lot of things, the biggest piece is if you need aggregation (in the event you have duplicate indices) or not (i.e. every index is unique and you’re just basically transposing). Can you provide a Minimal Reproducible Example that has a CDS with data, and a description of what you’d like the pivot piece to do?
Right so you are predefining columns, predefining the aggregation (3 averages and a count). Are you predefining fields to groupby (in your example you are grouping by car type - compact/midsize etc). Are you only providing one groupby field at a time (e.g. only grouping data by car type, and never grouping by car type AND number of cylinders)?
Ok. I may not have bandwidth to write this all out explicitly for you but I can give some guidance on logic/what you need to implement.
First of all, you absolutely can do this with bokeh and it’s awesome Secondly though, it’s gonna take more effort than you probably want, primarily due to the standalone requirement. To build standalone you will need CustomJS, and you essentially need CustomJS that will do the pseudocode “SQL-ish” equivalent of:
select avg(fieldyouwantaverage), count(fieldyouwanttocount) --i.e. all your aggregations
from your CDS where CDS indices are selected --i.e. everything from your CDS that is currently selected
group by [fieldyouwanttogroupby],[anotherfieldyouwanttogroupby] --i.e. doing the aggregation in groups as per certain fields
I would avoid writing vanilla JS code to do this, but rather look to leveraging existing JS libraries. d3 (d3.group, d3.rollup, d3.index / D3 / Observable) can do this, and maybe simpler but not as robust (e.g. no custom aggregation etc) alasql (http://alasql.org/) can also.
The overall logic would be
store your data in a CDS (i.e. the “primary” datasource)
instantiate another CDS (i.e. the “aggresult” datasource), with column names equivalent to what you want your pivot table to be and empty lists as their initial values
plot your “primary” CDS with the user ability to select it (lasso select etc.)
create a table with columns, running off off your “aggresult” datasource
write a callback that will:
a) complete the above outlined pseudo-sql logic
b) update the “aggresult” datasource with that result
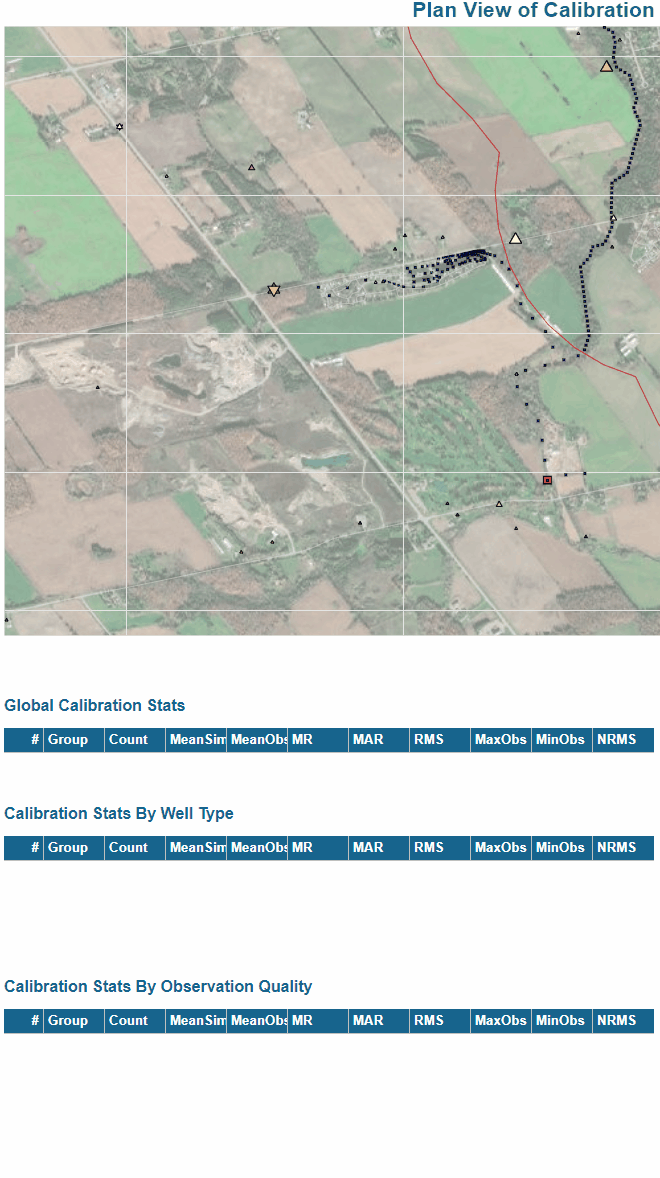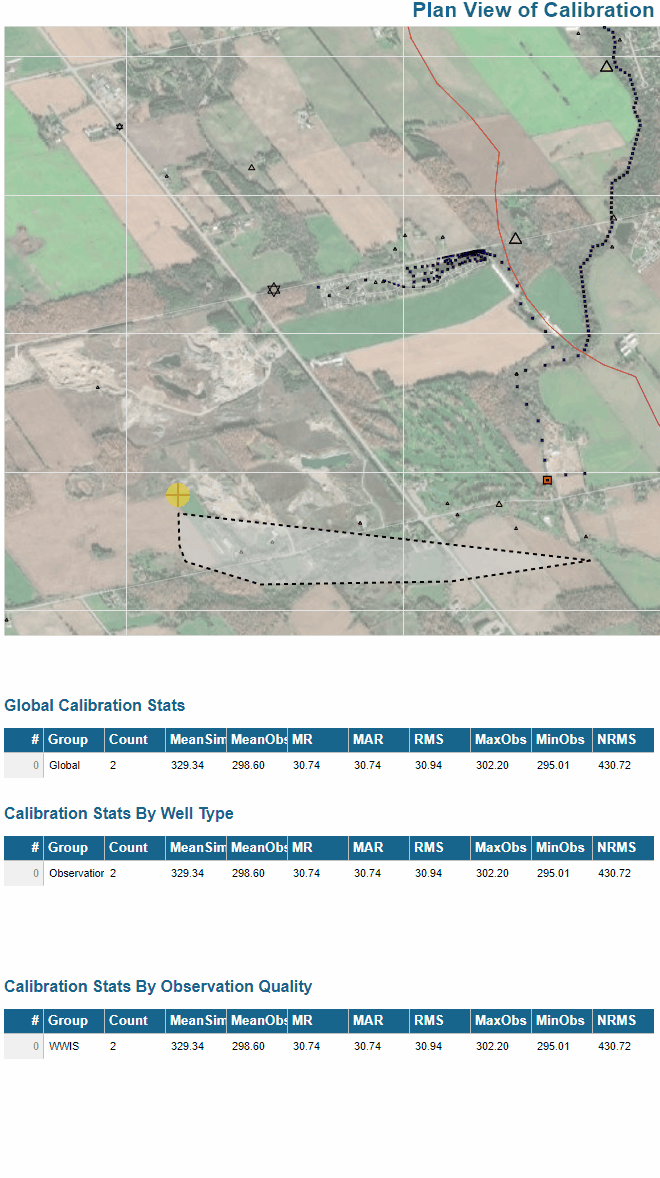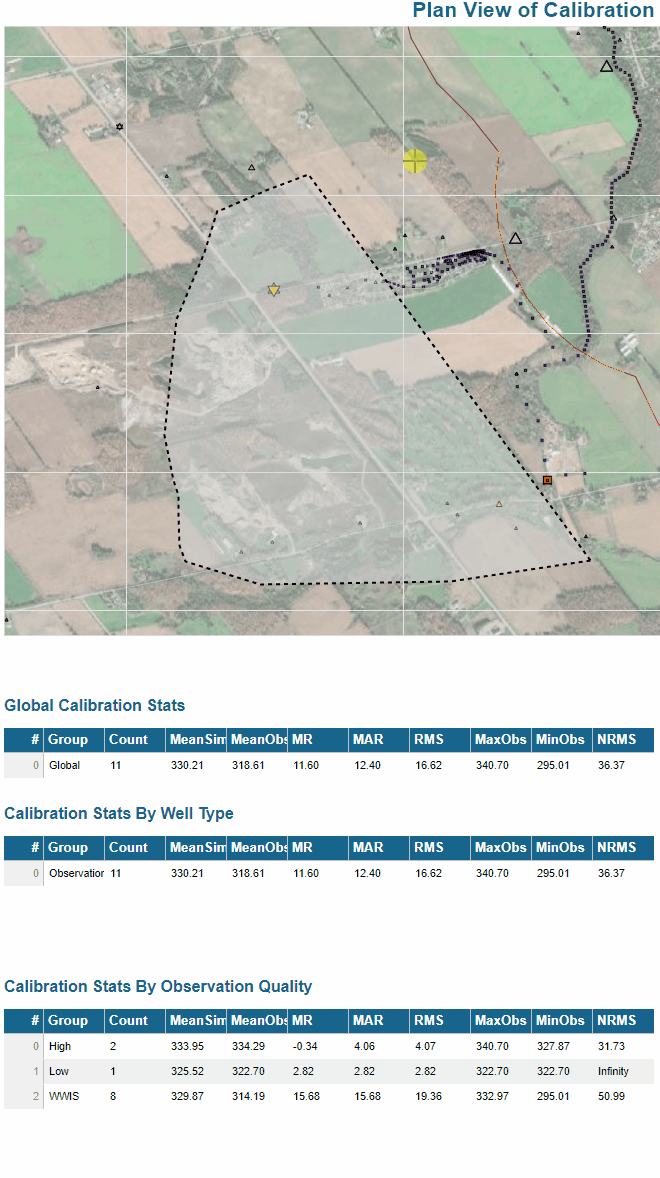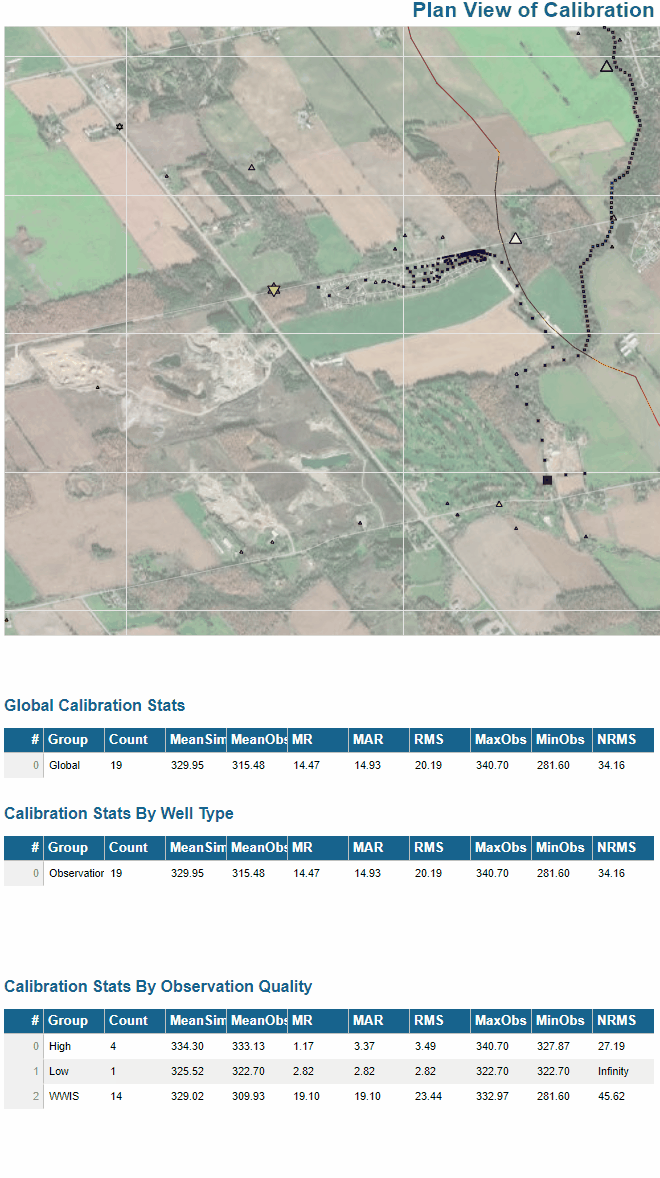
I’ve built in essence the same thing for evaluating calibration statistics (i.e. goodness of model fit) over an arbitrary user-defined selection, grouping by multiple fields etc and presenting results in different tables on the fly:
I did this with d3 because the aggregation functions are custom, i.e. not just “AVG” “COUNT” etc. It took a fair bit of work and learning but payoff was worth it Good luck!
Thank you heaps, I actually thought of doing it as you described it but all I know is the js used in the documentation and examples.
I have actually started doing what you outlined, where I did the following:
original CDS for the plotted data
instantiate an empty CDS for the tables
in a callback: store the relevant indices of the original CDS
do the necessary calculations on the rows of the original CDS at the saved indices and store them into variables
push the variables into the empty CDS to be viewed as the rows for the table
I halted my work due to my sub-basic knowledge in JS, and thought there might be a more elegant and direct way around it. I couldn’t figure out how to groupby the data based on two fields and how can I do the calculations? Should I have a variable for each element of the grouped-by fields? i.e. 2searter,compact,midsize…etc? so if i were to use the manufacturer I’d have to instantiate 16 variables?
Finally, is it possible to use D3 functions inside bokeh callbacks?
See this example of how I “import” additional JS Resources into a bokeh html output so you have access to them in callbacks:
The rest is just google-fu and trial and error/riding the struggle bus on the JS side. D3 is an insanely powerful library but my pandas/sql-based intuition/thought process is repeatedly shot down by it , that’s why I suggested trying alasql which would let you basically write basic SQL directly in the callback.