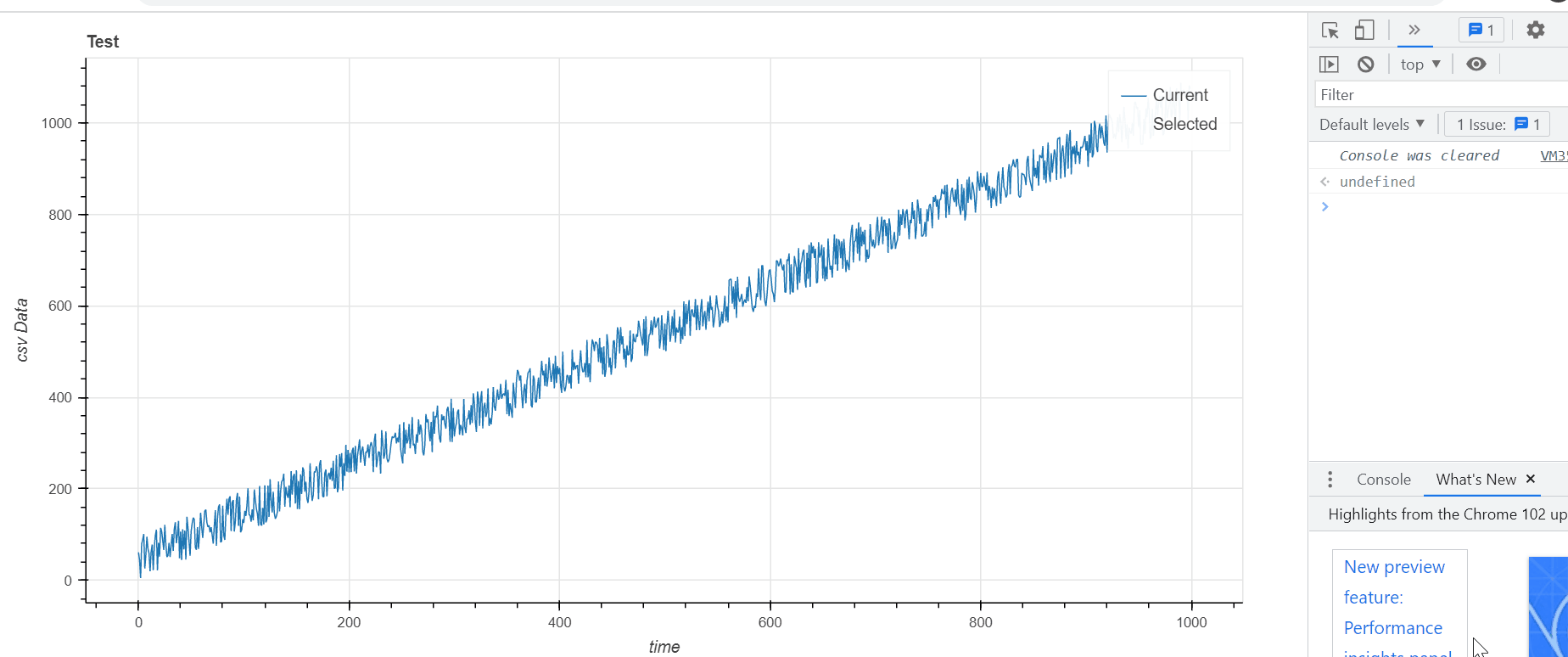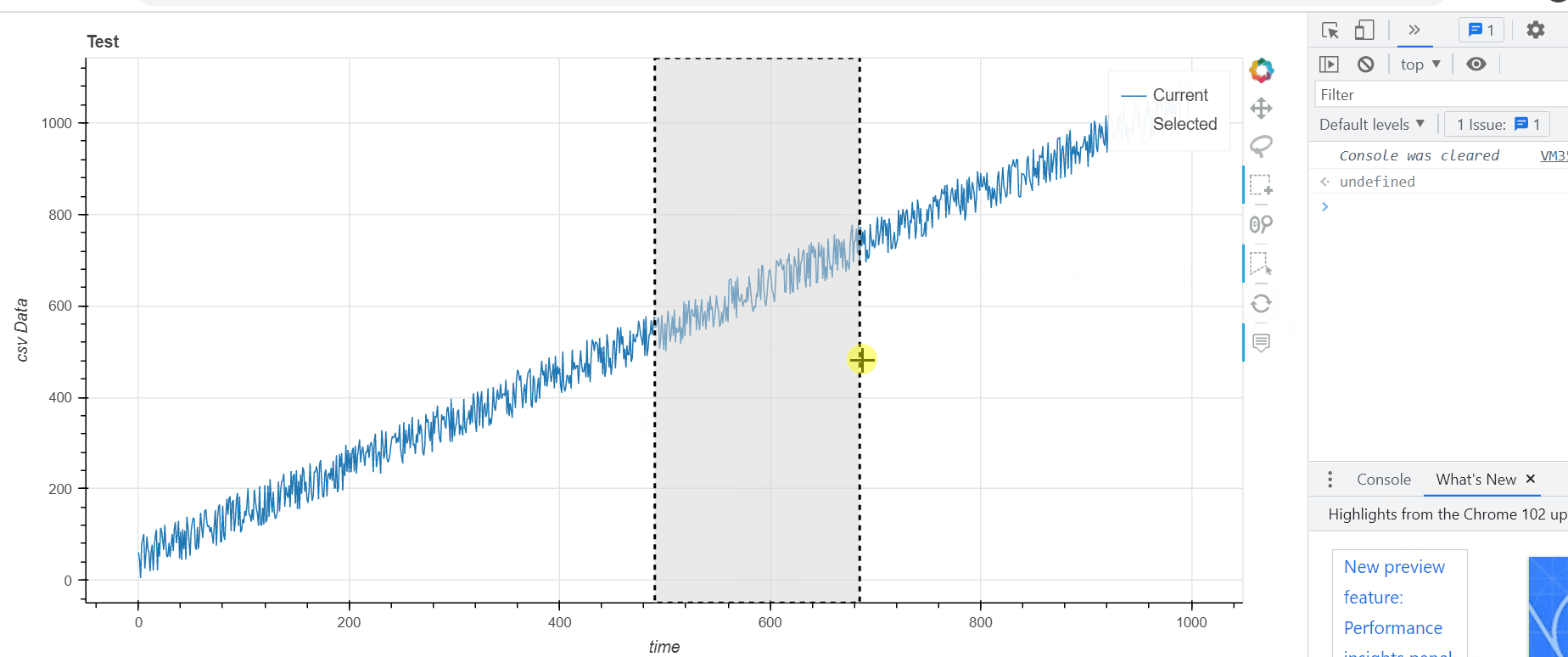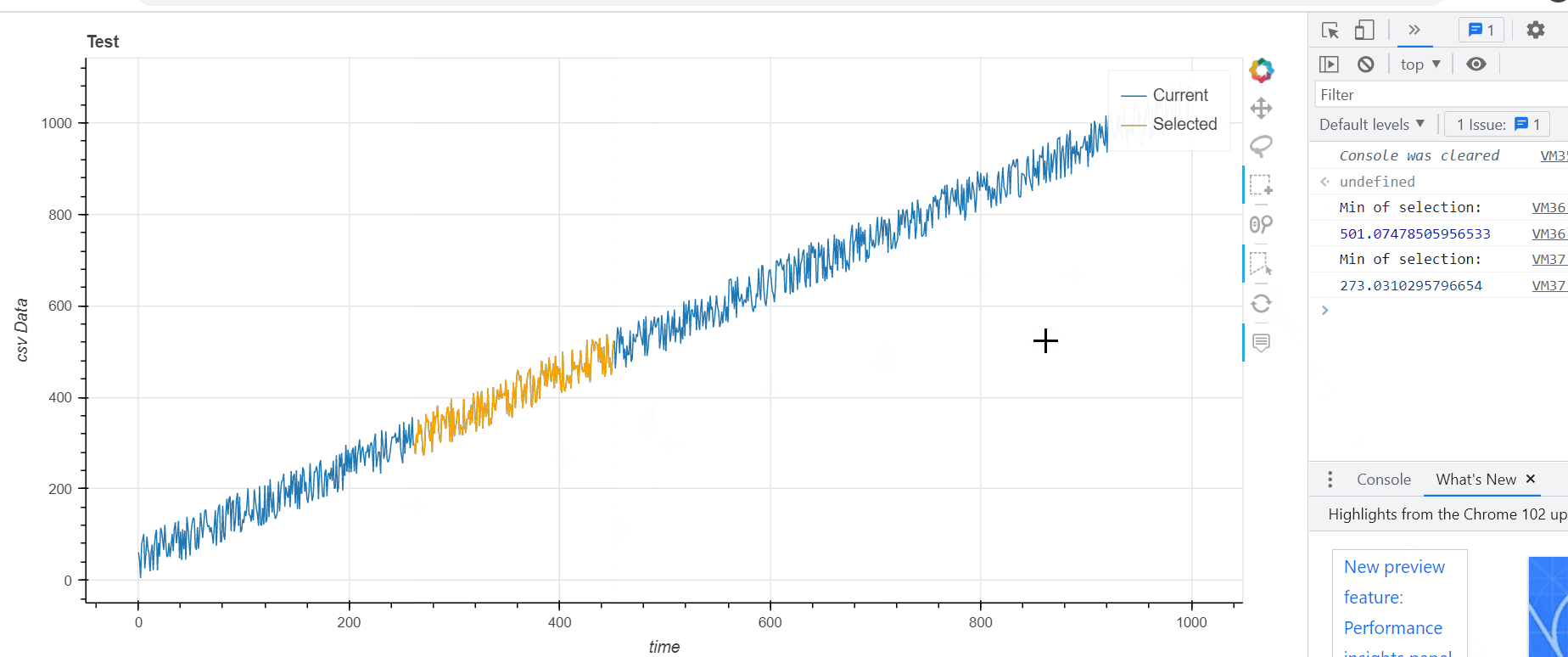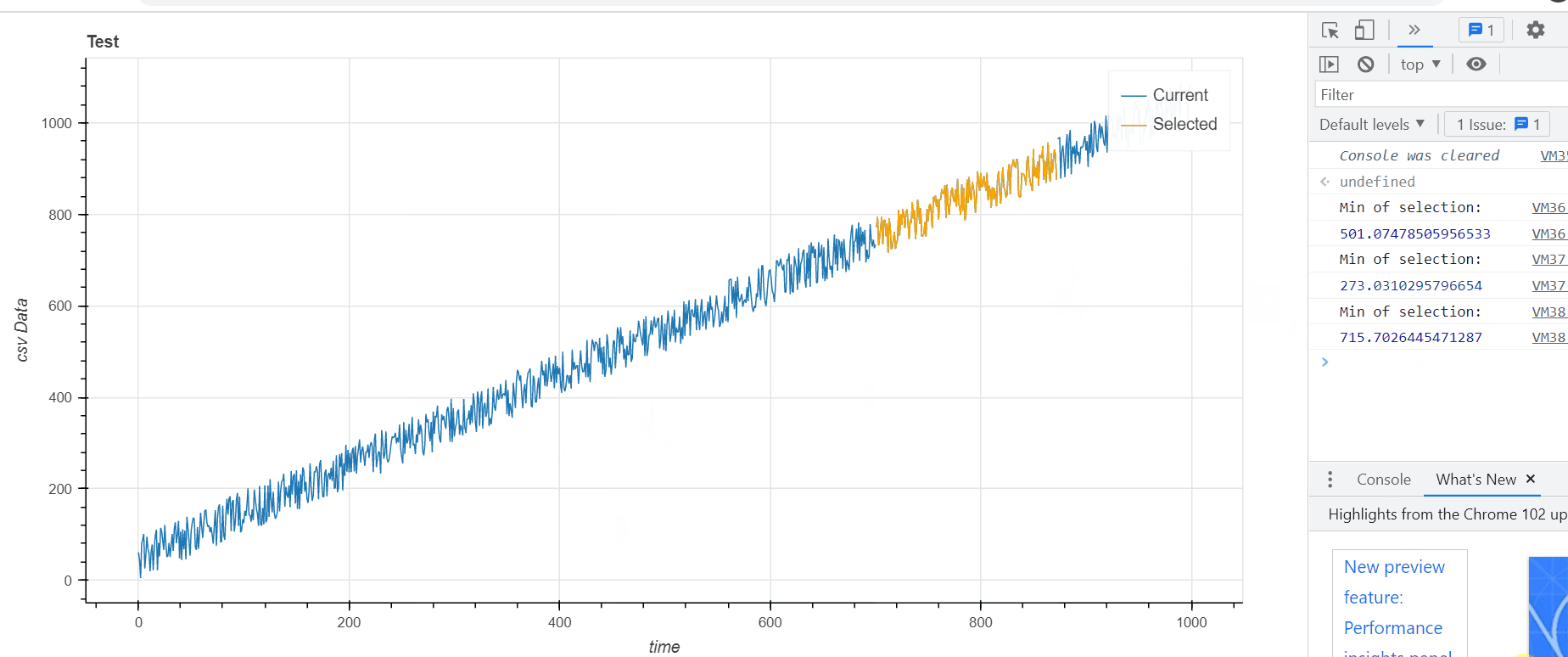
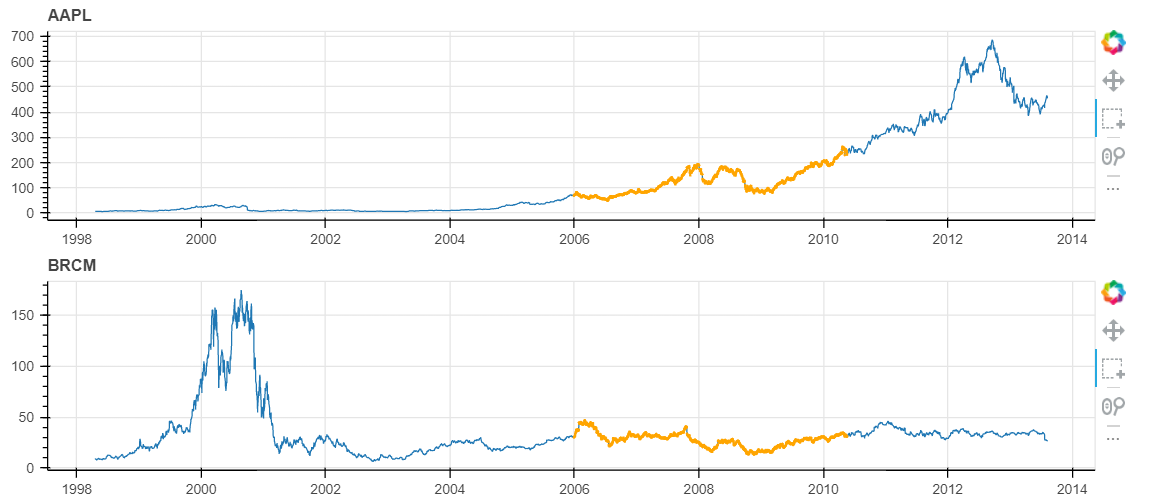
There are a number of ways to do this, but see my take on it here. I think your initial framework was good (e.g. having two sources, one for an orange selected line and another for the main blue line etc.). What was missing was the CustomJS component to execute what you want (i.e. update the source driving the selected line and also extract the min/max value of the selection). What was also missing was a little trick in creating a scatter renderer with 0 alpha running off the same main source as the main blue line. That way the selection tool can grab specifically the indices you selected.
Read the comments etc in the code to see the logic.
“”"
import numpy as np
import pandas as pd
from bokeh.plotting import figure,show,output_file
from bokeh.models import ColumnDataSource,CustomJS
output_file("PlottingTest.html")
#making random data
dataset = pd.DataFrame(data={'time':range(1000),'data':np.random.random(1000)*100+np.arange(1000)})
TOOLS ="pan,wheel_zoom,reset,hover,poly_select,xbox_select,lasso_select"
s1 = ColumnDataSource(data=dataset)
p = figure(title = 'Test',x_axis_label = 'time'
, y_axis_label='csv Data',plot_width=1000, plot_height=500,tools=TOOLS)
#create a line renderer of all data, pointing to s1 as the source
line_rend = p.line('time', 'data', legend_label="Current", line_width=1,source=s1)
#next step is to make the selection/nonselection glyphs of this line renderer identical to the "normal" line renderer
line_rend.selection_glyph = line_rend.glyph
line_rend.nonselection_glyph = line_rend.glyph
#now make a scatter renderer with zero alpha driving off the same ColumnDataSource
scatter_rend = p.scatter('time','data',fill_alpha=0,source=s1,line_alpha=0)
#do the the exact same thing as about with the selection glyphs and non selection glyphs
scatter_rend.selection_glyph = scatter_rend.glyph
scatter_rend.nonselection_glyph = scatter_rend.glyph
#now create a "selection source" (you had something like this already)
#initialize with no data
sel_src = ColumnDataSource(data={'time':[],'data':[]})
#make a renderer running off this source, orange line
sel_line_render = p.line('time','data',legend_label='Selected',line_color='orange',source=sel_src)
#now the JS component
#basically the alpha 0 scatter glyph will allow the selection tool to grab selected indices from s1
#we use those selected indices to collect the corresponding values from s1 for the time and data fields
#and push those values into arrays ("sel_time" and "sel_data")
#use Math.min etc to get the min/max values from that array... (not sure what you want to do with it but I have it logging in the console)
#then use the sel arrays to populate the sel_src, which your orange line is running off of... so it'll do what you want
cb=CustomJS(args=dict(s1=s1,sel_src=sel_src)
,code='''
var sel_inds = s1.selected.indices
var sel_time = []
var sel_data = []
for (var i=0;i<s1.selected.indices.length;i++){
sel_time.push(s1.data['time'][sel_inds[i]])
sel_data.push(s1.data['data'][sel_inds[i]])}
console.log('Min of selection:')
console.log(Math.min(...sel_data))
sel_src.data['time']= sel_time
sel_src.data['data'] = sel_data
sel_src.change.emit()
''')
#tell this callback to happen whenever the selected indices of s1 change
s1.selected.js_on_change('indices',cb)
p.toolbar.autohide = True
show(p)