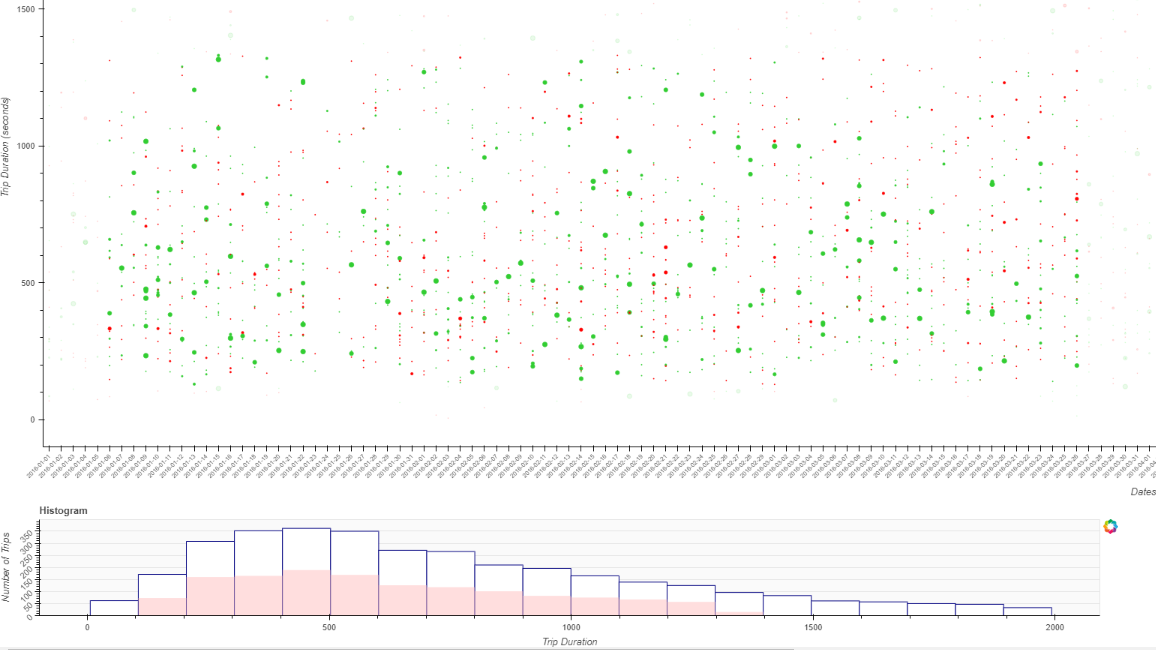
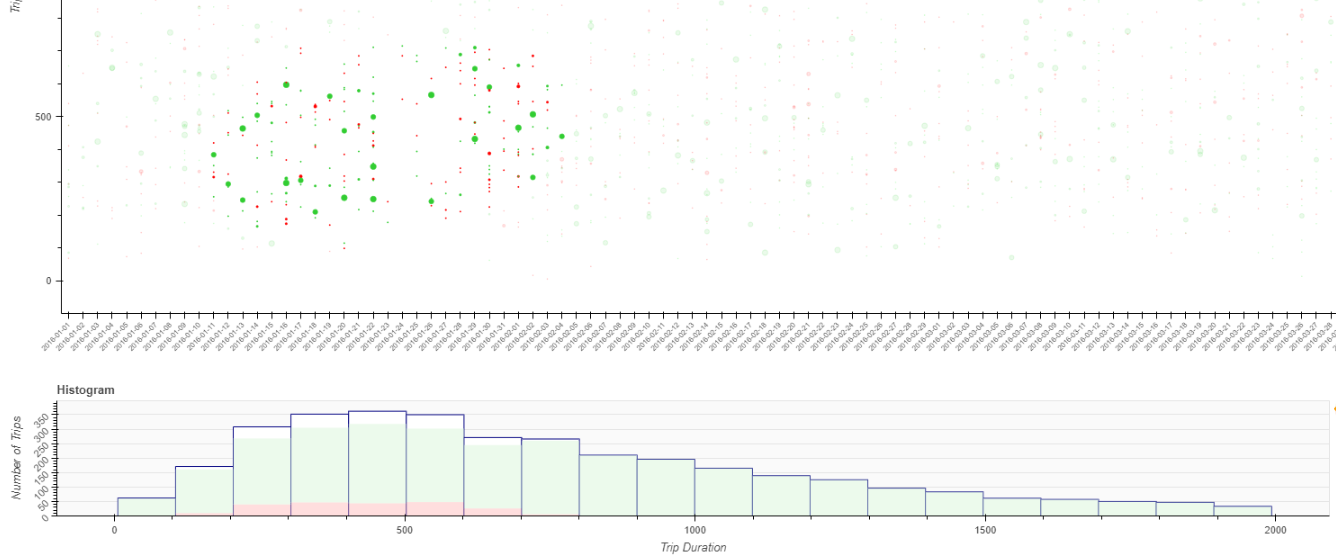
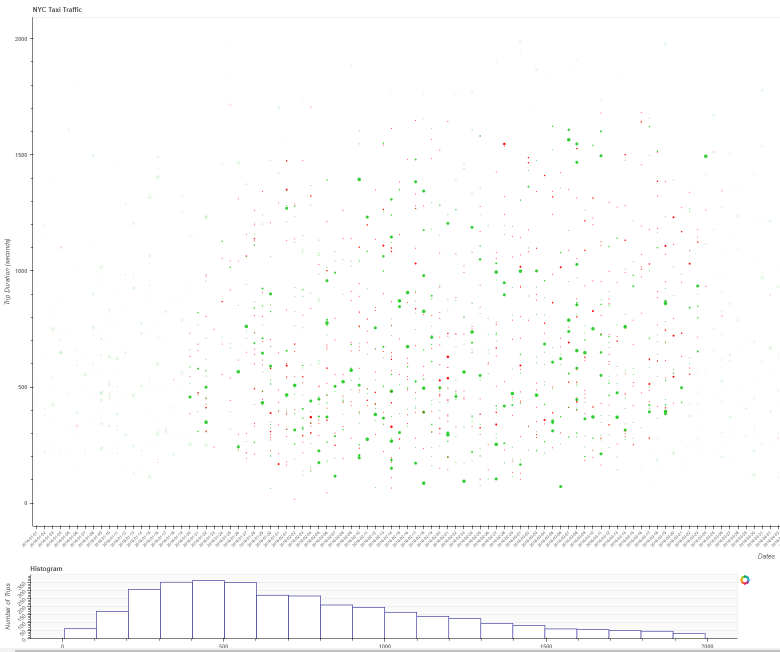
Hello everyone. I’m working on an exercise where a lasso and/or box select tool highlights the area of a histogram according to what was selected on a scatter plot. The problem I’m facing is that the histogram won’t fill the colors for the respective selection. I believe I’m not implementing the interactions correctly. Here is my full code below.
Import required libraries
import pandas as pd
import numpy as np
from bokeh.io import output_file, show, save,curdoc, output_notebook
from bokeh.plotting import figure
from bokeh.models import ColumnDataSource, HoverTool,FactorRange, NumeralTickFormatter,HBar, DatetimeTickFormatter
from bokeh.models.widgets import Select
from bokeh.layouts import column, row, gridplot
import bokeh.palettes as bp # uncomment it if you need special colors that are pre-defined
import datetime as dt
from math import pi
from bokeh.layouts import gridplot
from bokeh.models import BoxSelectTool, LassoSelectTool
Some dummy data
print(df_scatterplot.head(50))
dates trip_duration passenger_count vendor_id color
0 2016-01-01 257 1 vendor_2 #32CD32
1 2016-01-01 86 2 vendor_2 #32CD32
2 2016-01-01 1147 1 vendor_2 #32CD32
3 2016-01-01 540 1 vendor_1 #FF0000
4 2016-01-01 411 1 vendor_1 #FF0000
5 2016-01-01 227 2 vendor_2 #32CD32
6 2016-01-01 474 1 vendor_2 #32CD32
7 2016-01-01 473 1 vendor_1 #FF0000
8 2016-01-01 654 1 vendor_2 #32CD32
9 2016-01-01 295 1 vendor_1 #FF0000
10 2016-01-01 69 1 vendor_1 #FF0000
11 2016-01-01 286 2 vendor_2 #32CD32
12 2016-01-01 998 1 vendor_2 #32CD32
13 2016-01-01 928 1 vendor_1 #FF0000
14 2016-01-01 295 2 vendor_2 #32CD32
15 2016-01-01 338 1 vendor_2 #32CD32
16 2016-01-02 1195 2 vendor_1 #FF0000
17 2016-01-02 407 2 vendor_2 #32CD32
18 2016-01-02 1898 1 vendor_1 #FF0000
19 2016-01-02 945 1 vendor_1 #FF0000
20 2016-01-02 223 2 vendor_2 #32CD32
21 2016-01-02 1141 1 vendor_1 #FF0000
22 2016-01-02 219 2 vendor_2 #32CD32
23 2016-01-02 290 1 vendor_2 #32CD32
24 2016-01-02 376 3 vendor_2 #32CD32
25 2016-01-02 632 1 vendor_1 #FF0000
26 2016-01-02 254 1 vendor_1 #FF0000
27 2016-01-03 1379 1 vendor_2 #32CD32
28 2016-01-03 745 1 vendor_1 #FF0000
29 2016-01-03 349 2 vendor_2 #32CD32
30 2016-01-03 540 3 vendor_2 #32CD32
31 2016-01-03 243 1 vendor_1 #FF0000
32 2016-01-03 731 1 vendor_1 #FF0000
33 2016-01-03 1388 1 vendor_1 #FF0000
34 2016-01-03 720 1 vendor_1 #FF0000
35 2016-01-03 1197 1 vendor_1 #FF0000
36 2016-01-03 512 1 vendor_2 #32CD32
37 2016-01-03 510 1 vendor_1 #FF0000
38 2016-01-03 751 6 vendor_2 #32CD32
39 2016-01-03 112 1 vendor_2 #32CD32
40 2016-01-03 424 6 vendor_2 #32CD32
41 2016-01-03 228 1 vendor_1 #FF0000
42 2016-01-03 819 1 vendor_1 #FF0000
43 2016-01-03 862 1 vendor_2 #32CD32
44 2016-01-03 828 1 vendor_1 #FF0000
45 2016-01-04 1238 1 vendor_2 #32CD32
46 2016-01-04 872 1 vendor_1 #FF0000
47 2016-01-04 1101 4 vendor_1 #FF0000
48 2016-01-04 649 6 vendor_2 #32CD32
49 2016-01-04 743 1 vendor_1 #FF0000
Here I create my ColumnDataSource, scatterplot, hover tools and selection tools.
data = {'Dates': list(df_scatterplot['dates']),
'TripDuration': list(df_scatterplot['trip_duration']),
'NumOfPass': list(df_scatterplot['passenger_count']),
'Vendor': list(df_scatterplot['vendor_id']),
'Color' : list(df_scatterplot['color'])
}
source_scatter = ColumnDataSource(data)
x_Range = list(dict.fromkeys(source_scatter.data['Dates']))
TOOLS="lasso_select, box_select, reset"
p = figure(tools=TOOLS, plot_width=3000, plot_height=900,
toolbar_location="above",x_range = x_Range,
title="NYC Taxi Traffic")
p.yaxis.axis_label = "Trip Duration (seconds)"
p.xaxis.axis_label = "Dates"
p.xaxis.major_label_orientation = pi/4
p.xaxis.major_label_text_font_size = '8px'
p.xgrid.grid_line_color = None
p.ygrid.grid_line_color = None
p.sizing_mode = "stretch_both"
p.select(LassoSelectTool).select_every_mousemove = False
p.select(BoxSelectTool).select_every_mousemove = False
hover = HoverTool(tooltips = [
('Date','@Dates'),
('Trip Duration','@TripDuration'),
('Number of Passengers','@NumOfPass'),
('Vendor ID','@Vendor')
])
p.add_tools(hover)
scatter = p.scatter(x='Dates',y='TripDuration',size='NumOfPass',color='Color',source=source_scatter)
Here I create my histogram for the trip duration. This is also where I have some bokeh warnings.
hhist, hedges = np.histogram(a=df_scatterplot['trip_duration'],bins=20)
hzeros = np.zeros(len(hedges)-1)
hmax = max(hhist)*1.1
LINE_ARGS1 = dict(color="#ffbdbd", line_color=None)
LINE_ARGS2 = dict(color="#d9f5d9", line_color=None)
ph = figure(title="Histogram", tools='', background_fill_color="#fafafa", plot_width=1500, plot_height=200, x_range=p.y_range, y_range=(0, hmax))
ph.xgrid.grid_line_color = None
ph.yaxis.major_label_orientation = np.pi/4
ph.quad(top=hhist,bottom=hzeros,left=hedges[:-1],right=hedges[1:],fill_color='white', line_color='navy')
ph.y_range.start = 0
ph.yaxis.axis_label = "Number of Trips"
ph.xaxis.axis_label = "Trip Duration"
# Create two more histogram quads for selected data.
# These two quads will be manipulated by the selection tools. When we select data from the scatter plot, we want histogram to be highlighted with the parts that
# corresponds to our data points. Therefore, we need two more quads to indicate the highlighted area. The color will be the same but we will
# use the alpha value = 0.5
hh1 = ph.quad(top=source_scatter.selected.indices,bottom=hzeros,left=hedges[:-1],right=hedges[1:], alpha=0.5,**LINE_ARGS1)
hh2 = ph.quad(top=source_scatter.selected.indices,bottom=hzeros,left=hedges[:-1],right=hedges[1:], alpha=0.5,**LINE_ARGS2)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('top', 0)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('left', 20), ('top', 0)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('left', 20), ('right', 20), ('top', 0)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('top', 0)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('left', 20), ('top', 0)
BokehUserWarning: ColumnDataSource's columns must be of the same length. Current lengths: ('bottom', 20), ('left', 20), ('right', 20), ('top', 0)
Finally the update function and layout creation.
# Implement the update function that will be triggered when the lasso or box selection tool is used.
def update(attr, old, new):
nds = new # index of the data that are selected
hh1.selected.nds
hh2.selected.nds
pass
scatter.data_source.selected.on_change('indices', update)
layout = column(p, row(ph))
curdoc().add_root(layout)
The following plot produces after using the lasso tool
cd path
bokeh serve --show code_file.ipynb
However, the histogram should be filled after my select with one of the tools like so

Where did I go wrong in my code above? I’m sure it’s very minor but I can’t see it. Thanks in advance.