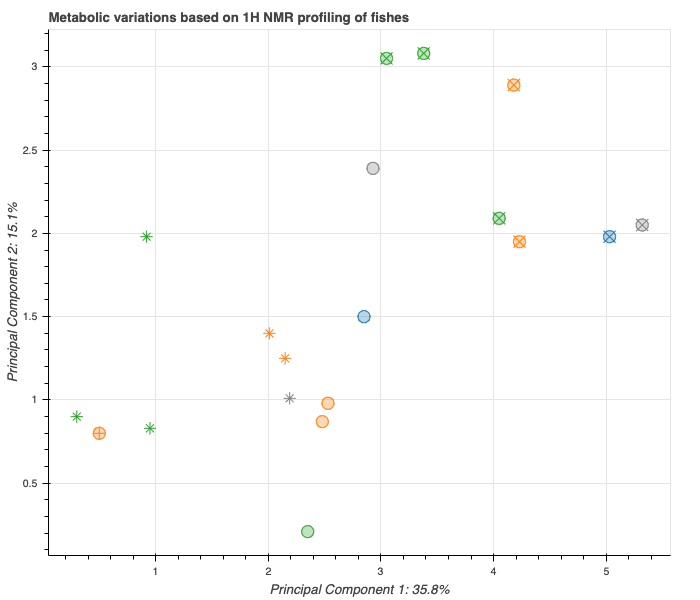
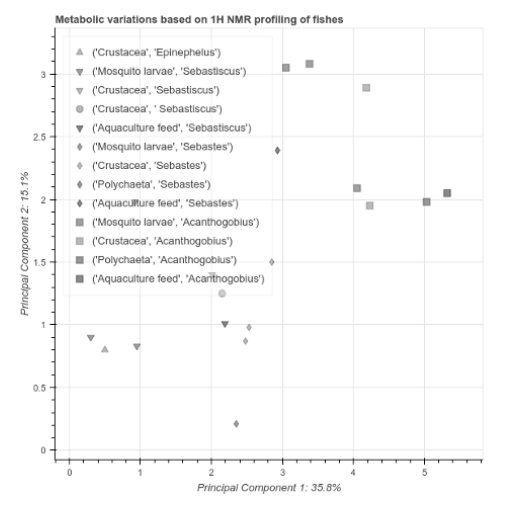
I wonder how to put a legend with both fields, as in the original image. Legend accepts only a string with the name one field, but I need to enter two. What can I do?
@sbassi please edit your post, the first image did not come through (and I don’t really remember what it might look liked, bokeh.charts was removed several years ago at this point).
Create a CDS column feeds_and_species that just combines the feeds and species column values the way you want them to be displayed on the legend. Then just pass legend_field='feeds_and_species' into p.scatter
Create the whole legend manually. It will allow you to avoid having to create a special column, but it will require you to create bogus markers for each row. If you’re not sure how to do this, then definitely go with the other option
Hello, thanks for your post and for posting the picture (I was not allowed to post it since it triggered an anti spam property of this forum since it was my first post).
been trying to implement first option, with no success. I am no familiar with ColumnDataSource. You said “Create a CDS column…” and “Then just pass…”, but I understand that this CDS column should replace the source I am using now, that is the DataFrame, isn’t it?
Would you give me another advise?
Here is the date source: Py4Bio/fishdata.csv at master · Serulab/Py4Bio · GitHub
Best,
SB
In this case you’re not dealing with ColumnDataSource. But that’s only because Bokeh converts Pandas’ DataFrame to Bokeh’s ColumnDataSource implicitly when you pass it as source=ds.