I’ve created a pandas dataframe, from which I instanciated a ColumnDataSource for building a DataCube. My issue is: the DataCube sorts my data in a different way that both the dataframe and the source are sorted, and I didn’t find any kind of configuration to set this behaviour up.
Hi @diegospereira, the example in the examples directory seems to present the data sorted according to the order the columns are given in. I am not sure there is any different behavior that is configurable at present. In order to speculate about anything you would need to provide a minimal complete examples that could be run to see what you are seeing.
Sure thing!
This code reproduces what I’m facing:
from bokeh.plotting import show, figure
from bokeh.models import ColumnDataSource, TableColumn
from bokeh.models.widgets.tables import (DataCube, GroupingInfo, SumAggregator,
StringFormatter, NumberFormatter)
import pandas as pd
import numpy as np
# sample data generation
queries = [f'query{i}' for i in range(100)]
pages = [f'page{i}' for i in range(20)]
size = 1000
data = {
'page': np.random.choice(pages, size),
'query': np.random.choice(queries, size),
'impressions': np.random.randint(0, 1000, size)
}
output_notebook()
df = pd.DataFrame(data)
# These index are user just for sorting the dataframe
index1 = df.groupby(['query'])['impressions'].agg(pd.Series.sum)
index2 = df.groupby(['query', 'page'])['impressions'].agg(pd.Series.sum)
df = (df
.groupby(['query', 'page'])
.agg({
'impressions': pd.Series.sum
}))
for (query, page), val in index2.items():
df.loc[(query, page), 'sort1'] = index1[query]
df.loc[(query, page), 'sort2'] = val
df.sort_values(by=['sort1', 'sort2'], ascending=False, inplace=True)
df.drop(['sort1', 'sort2'], axis=1, inplace=True)
df.reset_index(inplace=True)
source = ColumnDataSource(df)
target = ColumnDataSource(data=dict(row_indices=[], labels=[]))
str_formatter = StringFormatter(font_style='bold')
num_formatter = NumberFormatter(format='0.[00]')
pct_formatter = NumberFormatter(format='0.0[0]%')
columns = [
TableColumn(field='page', title='Query', width=120, sortable=False, formatter=str_formatter),
TableColumn(field='impressions', title='Impressões', width=40, sortable=False)
]
grouping = [
GroupingInfo(getter='query', aggregators=[SumAggregator(field_='impressions')])
]
cube = DataCube(source=source, columns=columns, grouping=grouping, target=target, width=1000)
show(cube)
On the left, it is shown the DataCube result, on the right, the table from the same source:
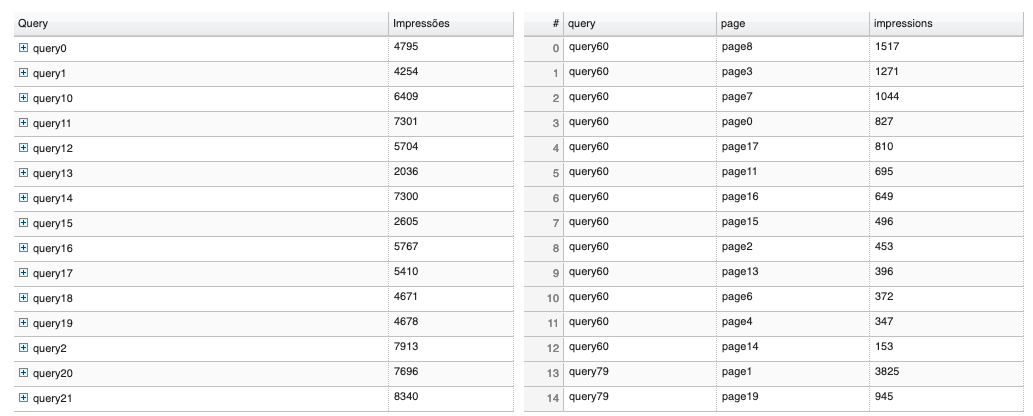
Is there a way to sort the DataCube rows the same way the source rows are sorted?
@diegospereira Right, as I mentioned, it is sorting the first column by value, and since the the first column is strings, it is sorting lexicographically, means, e.g. “query19” is less then “query2”. So the results are exactly what I would expect. AFAIK there is not currently any way to modify or turn off this default sorting scheme. Longer term, you could make a GitHub issue to request some control over the sorting. Short term the only suggestion I have if for you to pad the numbers in the values with leading zeros. I.e., “query02” instead of “query2”. Then things will sort the way you want (if I understand what you want).