Might have ran across something when playing w/ DataTable() and TableColumn().
The goal was to keep a generic DataTable around to catch unknown data. TableColumn fields would be keys and known data mapped onto them in subsequent server updates.
If you toggle your title w/out also matching the field, the data won’t propagate.
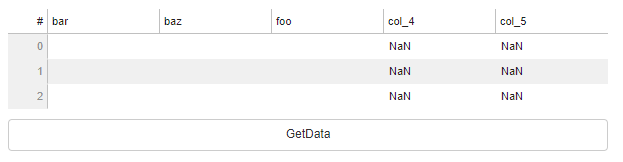
I expected the cds to map to the underlying fields and treat the titles as cosmetic.
Am I crazy?
from bokeh.io import curdoc
from bokeh.plotting import figure, show
from bokeh.layouts import column, row
from bokeh.models import ColumnDataSource, CDSView, IndexFilter
from bokeh.models import Button, PreText, TableColumn, DataTable
from bokeh.io import show, output_notebook
from bokeh.resources import INLINE
import pandas as pd
import numpy as np
def bkapp(doc):
#pretend to not know the data
data = pd.DataFrame.from_records({'col_1': None , 'col_2': None, 'col_3': None, 'col_4':None, 'col_5':None}, index=[0])
columns = [TableColumn(field=n, title=n) for n in data.keys()]
#create a source and mxn table, all datasource updates w/ have to adhere to column count
source = ColumnDataSource(data)
data_table = DataTable(source=source, columns=columns, height=100)
def select_file():
#visual indicators
data_table.visible = True
#grab the new data
new_data = dict(
foo=[randint(0, 100) for i in range(3)],
bar=[randint(0, 100) for i in range(3)],
baz=['a','b','c'],
)
new_data = pd.DataFrame.from_records(new_data)
#creater a mapper for table to update col names | not fields, just display titles, fields are preserved
mapper = dict(itertools.zip_longest(data_table.columns, new_data.columns, fillvalue=None))
#update the table for found data and fit vanilla cds
for k,v in mapper.items():
if v is not None:
#column title and field are not independent
k.title = v
#k.field = v
continue
else:
#if v is None add to new_data
new_data = new_data.reindex(columns=new_data.columns.tolist() + [k.title])
#send the data
source.data = new_data
def remove_col():
#remove first column
x = data_table.columns[0]
x.visible=False
btn = Button(label="GetData")
btn.on_click(select_file)
doc.add_root(column(data_table, btn))