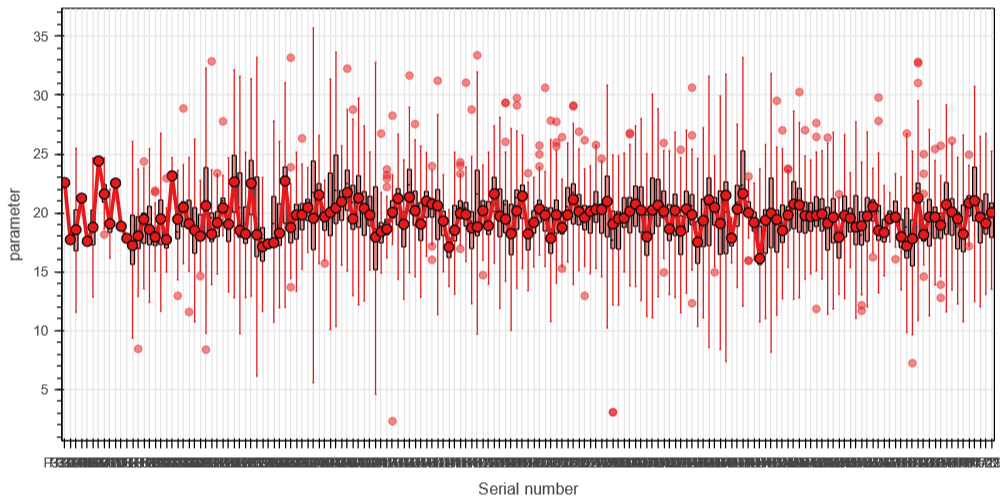
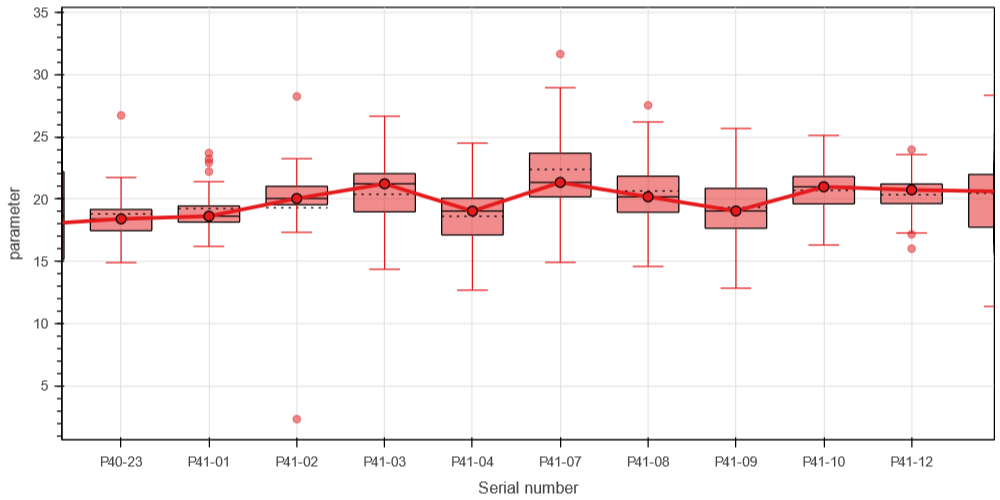
I have a plot that has some ordered sequence of strings (say, serial numbers of experiments) at x-axis. The sequence can be mapped to a (continuous?) integer series.
As far as I understand, CategoricalAxes are usually used for this.
Unfortunately, when there are a lot of such categories, visual overlap occurs.
Is there any “idiomatic way” for visual thinning of xticklabels for CategoricalAxes at current scale (like for DateTimeAxis or LinearAxis) so that recalculation to a new scale occurs when zooming?
Moreover I think the LinearAxis is more suitable if the mapping like {int xvalue : str view} is possible.
@dinya You can use bounds to limit axis labels to just a certain range (link, link). And you can use min_interval on an axis ticker to control interval between ticks (link).