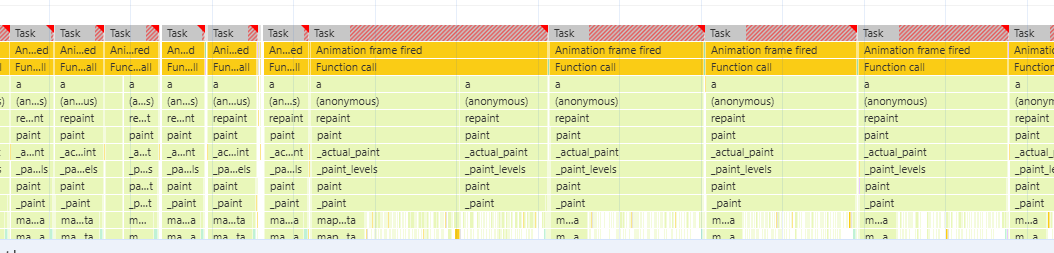
I have noticed that plotting data with one single line is signicantly worse (e.g. panning) vs. splitting it up into segments via multi line. Is this to be expected?
import numpy as np
from bokeh.io import curdoc
from bokeh.layouts import row
from bokeh.models import ColumnDataSource
from bokeh.plotting import figure
n_splits = 100
n_split_samples = 10_000
cds_standard = ColumnDataSource(data={"x":[], "y":[]})
cds_multi = ColumnDataSource(data={"x":[], "y":[]})
for i in range(n_splits):
x_data = np.arange(n_split_samples)
y_data = np.sin(x_data/100) + x_data/500*np.random.randn()
cds_standard.stream({"x": x_data, "y": y_data})
cds_multi.stream({"x": [np.append(x_data, x_data[0])], "y": [np.append(y_data, y_data[0])]})
p1 = figure(title="Single line", output_backend="webgl")
p2 = figure(title="Multi line", output_backend="webgl")
p1.line(x="x", y="y", source=cds_standard)
p2.multi_line(xs="x", ys="y", source=cds_multi)
print(cds_standard.data)
curdoc().add_root(row(p1, p2))
I’m not sure I understand the reason for a comparison between these two approaches, since the output between them is so different (you can see how each “subline” of the singe line version traces an additional straight segment back to the beginning that the multi-line version does not—entirely expected).
That said, I am also not sure why the line version is slower (FWIW only a little slower with a dev 3.7 build on my laptop). @Ian_Thomas is the person who could possibly provide technical details about WebGL.
Yes, this is expected. line needs to do slightly more work that multi_line due to them supporting selection differently. With a multi_line you can select each of the “sub-lines”, so each of 100 in the example. With a line you can select individual points, so each of 10,000 in the example. Although nothing is selected in the example there is still a small overhead in calculation and passing data to the GPU.
@Bryan@Ian_Thomas Thank you for your comments & explanations. Now I’m mainly wondering about two things:
You both mention “littler slower” & “small overhead”. When I do some profiling with the example line is 3x slower than multiline. Is this still within expectations because to me this doesn’t seem to be a “small” overhead (Chrome)?
Are there any supported optimizations possible if it is known upfront that data will not be selected? Is it encouraged to utilize multi_line to reproduce a single line while gaining some performance? (Note: In my example I purposely skipped the connecting line between the sublines (out of laziness)).