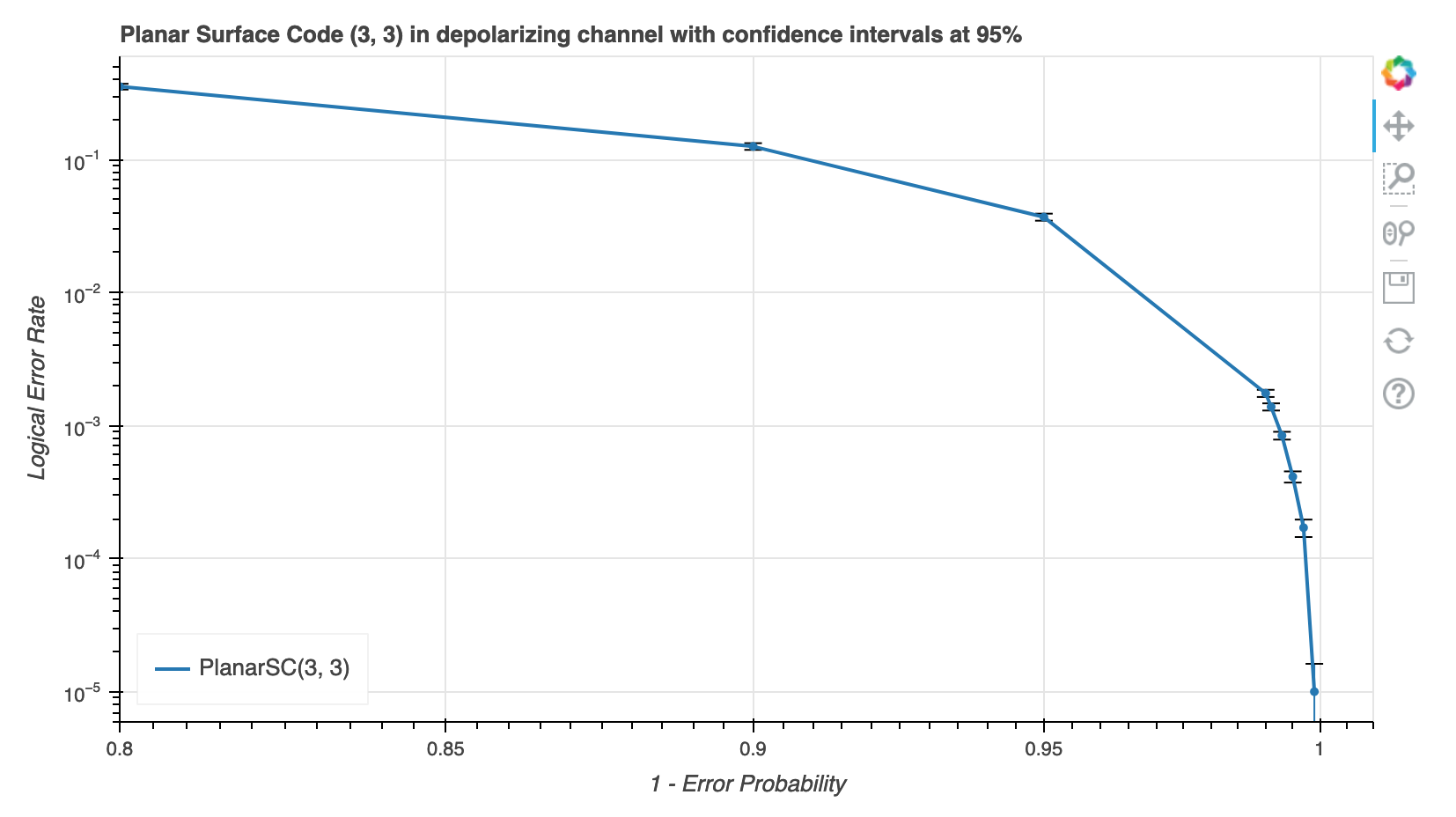
What are you trying to do?
I’m trying to plot some lines on a plot with both axis in log scale.
What have you tried that did NOT work as expected? If you have also posted this question elsewhere (e.g. StackOverflow), please include a link to that post.
I tried to change x_range because I read that including x=0 could mess up the log but that was not the case. I’m using Whisker so maybe there’s some kind of bug there with log scale?
If this is a question about Bokeh code, please post a Minimal, Reproducible Example so that reviewers can test and see what you see. A guide to do this is here:
I’m using a helper function to plot lines and whiskers:
def add_entry(p, x, y, n_tot, color=None, legend_label=None):
p.line(x, y, line_width=2, color=color, legend_label=legend_label)
p.circle(x, y, color=color)
CI_95 = np.sqrt(y * (1 - y) / n_tot) * np.sqrt(2) * erfinv(0.95)
source_error = ColumnDataSource(data=dict(base=x, upper=y + CI_95, lower=y - CI_95))
p.add_layout(Whisker(source=source_error, base="base", upper="upper", lower="lower", line_color=color))
return p
This is the code for the plot:
df = load_data(filepath)
p = figure(
title=f"Planar Surface Code ({col_qb}, {row_qb}) in depolarizing channel with confidence intervals at 95%",
sizing_mode="stretch_width",
max_width=800,
plot_height=450,
x_axis_label="1 - Error Probability",
y_axis_label="Logical Error Rate",
x_axis_type="log",
y_axis_type="log",
)
#p.xaxis.ticker = SingleIntervalTicker(interval=0.1)
p = add_entry(
p,
x=1 - df.error_probability,
y=df.logical_error_rate,
n_tot=df.decoded_codes,
color=palette[0],
legend_label="PlanarSC(3, 3)"
)
p.legend.location = "bottom_left"
show(p)